在数字化转型的浪潮中,微服务架构凭借其灵活性和可扩展性,已成为构建现代化应用的主流选择。容器技术,特别是以Docker和Kubernetes为代表的平台,为微服务的部署、管理和运维提供了理想的载体。有容云作为企业级云服务提供商,在帮助客户将核心数据处理服务进行微服务容器化落地的过程中,积累了大量实践经验,也面临并克服了诸多独特挑战。
面临的挑战
1. 数据状态与持久化难题
传统单体数据处理应用通常与数据库紧密耦合。将其拆分为多个微服务后,每个服务可能都需要独立的数据存储或缓存。在容器化环境中,容器的生命周期是短暂且易变的,如何确保数据处理过程中产生的中间状态、计算结果以及用户会话等数据的持久化与高可用,是一大挑战。简单的容器内存储会随着容器销毁而丢失,无法满足生产环境要求。
2. 服务间通信与数据流复杂性
数据处理流程往往涉及多个步骤(如采集、清洗、转换、分析、存储)。微服务化后,这些步骤成为独立的服务,它们之间的通信链路变得复杂。需要高效、可靠的通信机制(如gRPC、消息队列)来传递数据和控制指令,并处理网络延迟、服务发现、负载均衡以及通信失败重试等问题,确保数据流水线的完整性与时效性。
3. 资源调度与性能隔离
数据处理服务,尤其是进行实时分析或批量计算的任务,通常是资源消耗型(CPU密集型、内存密集型或I/O密集型)。在Kubernetes集群中,如何为不同特性的数据处理服务(如流处理服务与批处理服务)制定合适的资源请求(Requests)和限制(Limits),实现精细化的资源调度与隔离,避免服务间相互干扰,对集群的稳定性和整体吞吐量至关重要。
4. 配置与敏感信息管理
数据处理服务通常需要连接多种外部数据源(数据库、数据仓库、API等),涉及大量的连接字符串、认证密钥等配置信息。在容器化部署中,如何安全、一致且动态地管理这些配置和密钥,避免硬编码在镜像中,是实现安全与可管理性的核心。
5. 监控、日志与故障排查
微服务容器化后,服务实例数量动态变化,传统的监控和日志收集方式难以为继。需要建立统一的监控体系,能够追踪一个数据处理请求流经多个服务的完整链路(分布式追踪),并聚合所有容器的日志,以便快速定位性能瓶颈和故障点。
解决之道与实践
有容云针对上述挑战,结合云原生最佳实践,提出了系统性的解决方案。
- 持久化存储与有状态服务部署
- 策略:严格区分无状态服务与有状态服务。对于需要持久化数据的服务,使用Kubernetes的Persistent Volume (PV) 和 Persistent Volume Claim (PVC) 机制,对接高性能、高可靠的云存储(如云硬盘、文件存储)。
- 实践:为数据库、缓存(Redis)、消息队列(Kafka)等有状态中间件,以及需要保存检查点(Checkpoint)的流处理服务,配置动态存储供给。利用StatefulSet控制器来部署有状态服务,保障Pod的唯一性、稳定的网络标识和有序的部署/伸缩。
- 构建健壮的服务通信网格
- 策略:采用服务网格(Service Mesh) 技术(如Istio、Linkerd)来解耦业务逻辑与通信治理。
- 实践:通过服务网格实现细粒度的流量管理(金丝雀发布、A/B测试)、弹性能力(熔断、限流、重试)、安全的服务间mTLS加密以及可视化的服务依赖拓扑。对于异步数据处理流水线,广泛采用消息队列(如Apache Kafka、RabbitMQ)作为服务间的缓冲与解耦通道。
- 精细化资源管理与调度优化
- 策略:基于业务压力测试和监控数据,为每个微服务容器精确设置CPU和内存的Requests与Limits。
- 实践:利用Kubernetes的Horizontal Pod Autoscaler (HPA) 和 Vertical Pod Autoscaler (VPA),根据实时指标(如CPU利用率、自定义的队列长度)自动伸缩数据处理服务。对于特殊工作负载,使用节点亲和性/反亲和性、污点与容忍度等机制,将批处理任务调度到特定资源池,实现与在线服务的物理或逻辑隔离。
- 集中化的配置与密钥管理
- 策略:遵循“配置即代码”和“密钥与镜像分离”原则。
- 实践:使用Kubernetes ConfigMap 管理普通配置,使用 Secret 对象(并以加密形式存储)管理敏感信息。在更复杂的场景下,集成HashiCorp Vault等外部密钥管理系统,实现密钥的动态签发、轮转与细粒度访问控制。通过环境变量或卷挂载的方式注入容器。
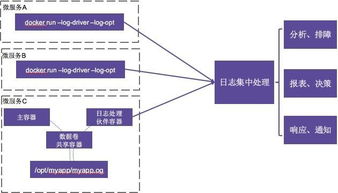
- 可观测性体系全覆盖
- 策略:构建集指标(Metrics)、日志(Logging)、追踪(Tracing) 于一体的可观测性平台。
- 实践:
- 指标:部署Prometheus收集Kubernetes核心指标及应用自定义指标(如数据处理吞吐量、延迟),通过Grafana进行可视化告警。
- 日志:采用EFK(Elasticsearch, Fluentd/Fluent Bit, Kibana)或Loki栈,由日志代理(DaemonSet形式)收集所有容器的标准输出和文件日志,实现集中存储与检索。
- 追踪:集成Jaeger或Zipkin,在服务代码中植入分布式追踪SDK,完整还原数据在微服务间的流动路径,便于进行性能分析和故障根因定位。
###
将有容云的数据处理服务进行微服务容器化改造,绝非简单的“搬站上云”,而是一场涉及架构、运维、安全与文化的系统性工程。成功的关键在于深刻理解数据处理服务的特性,识别核心挑战,并系统性地运用云原生技术栈中的持久化存储、服务网格、弹性伸缩、配置管理和可观测性等工具与模式。通过这一系列实践,企业能够构建出高可用、高弹性、易于运维且安全合规的现代化数据处理平台,从而更好地应对数据驱动时代的海量数据与复杂业务需求。